Reference Links
What I learned
- VGGNet is a neural network that performed very well (first place on the image localization task and second place on the image classification task) in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2014.
- (2014~) CNN Architecture becomes to make deeper network.
- Top Two teams, GoogLeNet team from Google and VGGNet team from Oxford Univ.
- The GooLeNet team designed complex but multifunctional modules called Inception and determined the entire CNN structure by stacking them.
- The VGGNet has a relatively easy and intuitive structure that appropriately adjusts the cumulative number of primary kernels to the desired filter size based on a very simple 3x3 convolution kernel.
- Factorizing Convolution
- Factorization
- By factorizing a large filter-sized convolution kernel, create a deep network consisting of several stages of small kernel
- which can reduce the number of free parameters and deepen the network than the original kernel.
- 5x5 convolution (25 parameters) can be factorized into 2 layers of 3x3 convolution (9+9 parameters) as below
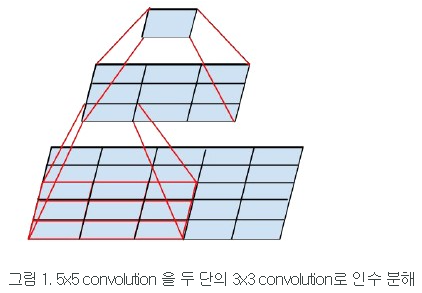
- 7x7 convolution (49 parameters) can be factorized into 3 layers of 3x3 convolution (9+9+9 parameters).
- 9x9 convolution (81 parameters) can be factorized into 4 layers of 3x3 convolution (9+9+9+9 parameters).
- 11x11 convolution (121 parameters) can be factorized into 5 layers of 3x3 convolution (9+9+9+9+9 parameters).
- Since the size of the feature-map decreases after the convolution operation is performed, it is essential to keep the feature-map size the same after the convolution operation through padding.
 Cool Wind on Study
Cool Wind on Study